
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- t-test
- lightsail
- FastAPI
- synflooding
- 다이나믹프로그래밍
- 딥러닝
- 보안
- 코딩테스트
- Python
- 리눅스
- 그리디
- linux
- 정보보안기사
- t검정
- 데이터사이언스
- 자료구조
- 보안기사
- 정보보안
- 카카오페이
- springboot
- 시간초과
- 카카오페이면접후기
- 파이썬
- 레디스
- 우선순위큐
- java
- 백준
- LangChain
- 분산시스템
- 프로그래머스
Techbrad
R를 활용한 KNN 실습 (iris 데이터) 본문
KNN 인접 기법 (k-nearest neighbor)
KNN는 머신러닝 기법 중의 한가지로 값을 분류하는 알고리즘이다. 분류와 군집은 비슷해 보이지만 목표값을 알고 분석하는 것은 분류(지도학습), 목표값을 모르고 유사한 것끼리 묶은 것을 군집(비지도학습)이라한다.
KNN은 지도학습의 한가지 기법이며 Instance - based Learning 으로 모델을 생성하지 않고 데이터를 분류하는데 사용됩니다. 즉 모델을 생성하지 않고 주어진 데이터를 갖고 바로 분석하기 때문에 오랜 시간이 걸린다.
KNN에 대해 그림으로 설명하지면 아래의 그림에서 보면 빨간색 점이 새로운 데이터라고 가정하자. 이를 Class A로 할지 Class B로 분류할지 막막하며 KNN은 K(주변 데이터의 수)값을 갖고 새로운 데이터를 분류한다.
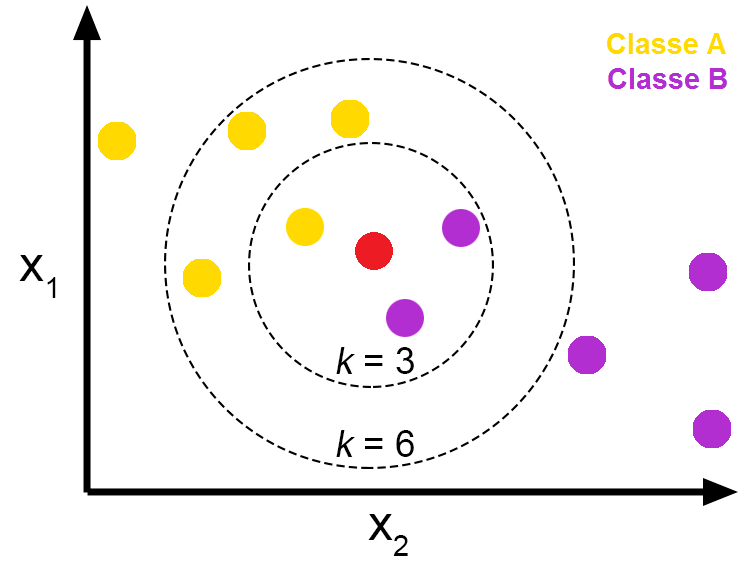
즉, K=3이라는 뜻은 새로운 데이터의 가장 가까운 3개의 데이터를 살펴보고 다수결의 법칙으로 많은 분류쪽으로 새로운 데이터를 정의하겠다라는 것이다. 만약 K=6인 경우에는 Class A가 많이 분포되어 있으므로 새로운 데이터는 Class A로 분류가 된다. 따라서 최적의 K를 찾아 오분류율을 최소화 하는 것이 KNN의 핵심이다.
※ 각 거리의 데이터의 거리는 아래와 같은 방식을 사용한다. (유클리디안 거리 법칙으로 실습)
● 범주형 변수 : Hamming distance
● 연속형 변수 : Euclidian distance, Manhattan distance
| library(class) library(gmodels) library(scales) iris<-read.csv("iris.csv", header = T, fileEncoding = "UTF-8-BOM") iris.train <- iris[tr.idx, -5] #knn 함수를 사용하여 예측값을 구하고 실제 값인 testLabels과 비교 |
CrossTable 결과
| | md1 testLabels | Setosa | Versicolor | Virginica | Row Total | -------------|------------|------------|------------|------------| Setosa | 16 | 0 | 0 | 16 | | 1.000 | 0.000 | 0.000 | 0.320 | | 1.000 | 0.000 | 0.000 | | | 0.320 | 0.000 | 0.000 | | -------------|------------|------------|------------|------------| Versicolor | 0 | 13 | 2 | 15 | | 0.000 | 0.867 | 0.133 | 0.300 | | 0.000 | 1.000 | 0.095 | | | 0.000 | 0.260 | 0.040 | | -------------|------------|------------|------------|------------| Virginica | 0 | 0 | 19 | 19 | | 0.000 | 0.000 | 1.000 | 0.380 | | 0.000 | 0.000 | 0.905 | | | 0.000 | 0.000 | 0.380 | | -------------|------------|------------|------------|------------| Column Total | 16 | 13 | 21 | 50 | | 0.320 | 0.260 | 0.420 | | -------------|------------|------------|------------|------------| |
표의 빨간색 글씨인 2가 오분류를 나타낸다. 예측값(md1)은 Virginica라고 예상했지만 실제값(testLabels)는 Versicolor이다. 따라서 총 50개의 데이터 중에 2개의 오분류가 나왔다.
하지만, 여기서 문제는 범위안에서 무조건 다수결의 법칙으로 분류한다면 정확하게 반영이 안될 수 도 있다.
예를 들어, K=3인 경우 가장 가까운 데이터는 A Class인데 나머지 멀리 있는 데이터가 B Class인 경우 어느 쪽으로 분류해야할지 애매한 경우가 발생한다.
따라서 이를 더 자세히 분류하기 위해 거리에 따라 ‘가중치’를 사용합니다. 즉, 근접한 데이터에 많은 가중치를 주어 보다 더 정확한 분류를 하는 것이다. (가중치를 적용하는 것은 다음에...)
'AI & BigData > Basic' 카테고리의 다른 글
| [Python] 파이참 프로젝트에 아나콘다 가상환경 적용하기 (0) | 2022.09.20 |
|---|---|
| Python을 활용한 KNN 실습 (iris데이터) (0) | 2020.12.27 |
| R, Python을 활용한 Paired Sample t-test (대응 표본 t 검정) (0) | 2020.12.15 |
| R, Python을 활용한 Independence two Sample t-test (독립 표본 t 검정) (0) | 2020.12.13 |
| R, Python을 활용한 One Sample t-test (단일 표본 t 검정) (0) | 2020.12.12 |

